
O3 & R1's Bitter Lesson - how AI Application companies will need to be Day 1 Model Agnostic
There have been 21 mentions of Deepseek in earnings calls so far but if you really want to know what is going on - listen to builders using AI

The Coffee Shop Conundrum
I recently overheard a snippet of conversation at a coffee shop in San Francisco:
Person 1: “O3 Mini just dropped, and it’s available in Cursor, but honestly, it’s still not as good as Sonnet.”
Person 2: “Is that an O3 problem or a Cursor problem?”
Person 1: “Definitely O3. I don’t blame Cursor.”
Person 2: “Why not?”
Person 1: “Cursor is just the interface. They let you pick which model you want to use.”
This holds a valuable lesson for every AI application builder: if you lock your users into a single model and the results aren’t up to par, YOU take the blame. But if you give users the flexibility to choose—and a particular model fails—the MODEL takes the hit instead.
At first glance, that might sound like a trivial user-experience detail, but it actually says something much deeper about where AI is headed—something that echoes Richard Sutton’s famous “Bitter Lesson.”
The Bitter Lesson
My co-founder Adit, a machine-learning researcher, has often pointed me to Richard Sutton’s seminal essay, The Bitter Lesson. Sutton, one of the founding fathers of reinforcement learning at DeepMind, argues that the approaches leveraging vast computation and search consistently outperform those that rely on handcrafted human knowledge or features. In other words: scale beats cleverness.
This principle crops up time and again in AI progress and has been re-enforced with Deepseek R1. Models that simply consume more data and more compute often stumble into tactics and insights that even the best human engineers never hard-coded. And that’s exactly what we’re seeing with the newest wave of foundation models.
You may say but OpenAI is using more scale and compute so how does the bitter lesson get emulated here. It is counterintuitive since Deepseek was trained on a much smaller budget ($6Mn) but the really interesting part was the algorithmic breakthrough that decided to do away with human feedback based reinforcement learning.
The “Aha Moment” in DeepSeek-R1-Zero
It is worth noting the “aha moment” we observed in the training of DeepSeek-R1-Zero. In the excerpt below, there’s a remarkable point in the model’s development when it starts to reevaluate its own approach—spending more “thinking time” on complex prompts.
A particularly intriguing phenomenon observed during the training of DeepSeek-
R1-Zero is the occurrence of an “aha moment”. This moment, as illustrated in Table 3, occurs in an intermediate version of the model. During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach. This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes.This moment is not only an “aha moment” for the model but also for the researchers observing its behavior. It underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. The “aha moment” serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems, paving the way for more autonomous and adaptive models in the future.
This is one of the most powerful affirmations yet of The Bitter Lesson: you don’t need to teach the AI how to reason, you can just give it enough compute and data and it will teach itself! - STRATECHERY [2]
Why is that such a big deal? Because no one explicitly taught DeepSeek-R1-Zero to backtrack or to be more reflective. The model spontaneously discovered that giving itself more internal deliberation led to better results. In other words, we just gave it the right incentives through reinforcement learning, and it invented an advanced problem-solving strategy on its own.
For researchers, seeing a model evolve its own meta-strategies feels like a revelation. But it’s also a testament to how letting scale and search run wild can yield emergent behaviors—and how little we often need to guide the process. This is precisely the demonstration of the Bitter Lesson: you don't teach the AI how to reason, you give it the platform (enough data and compute) so it can figure reasoning out on its own.
The New Reality for AI Startups
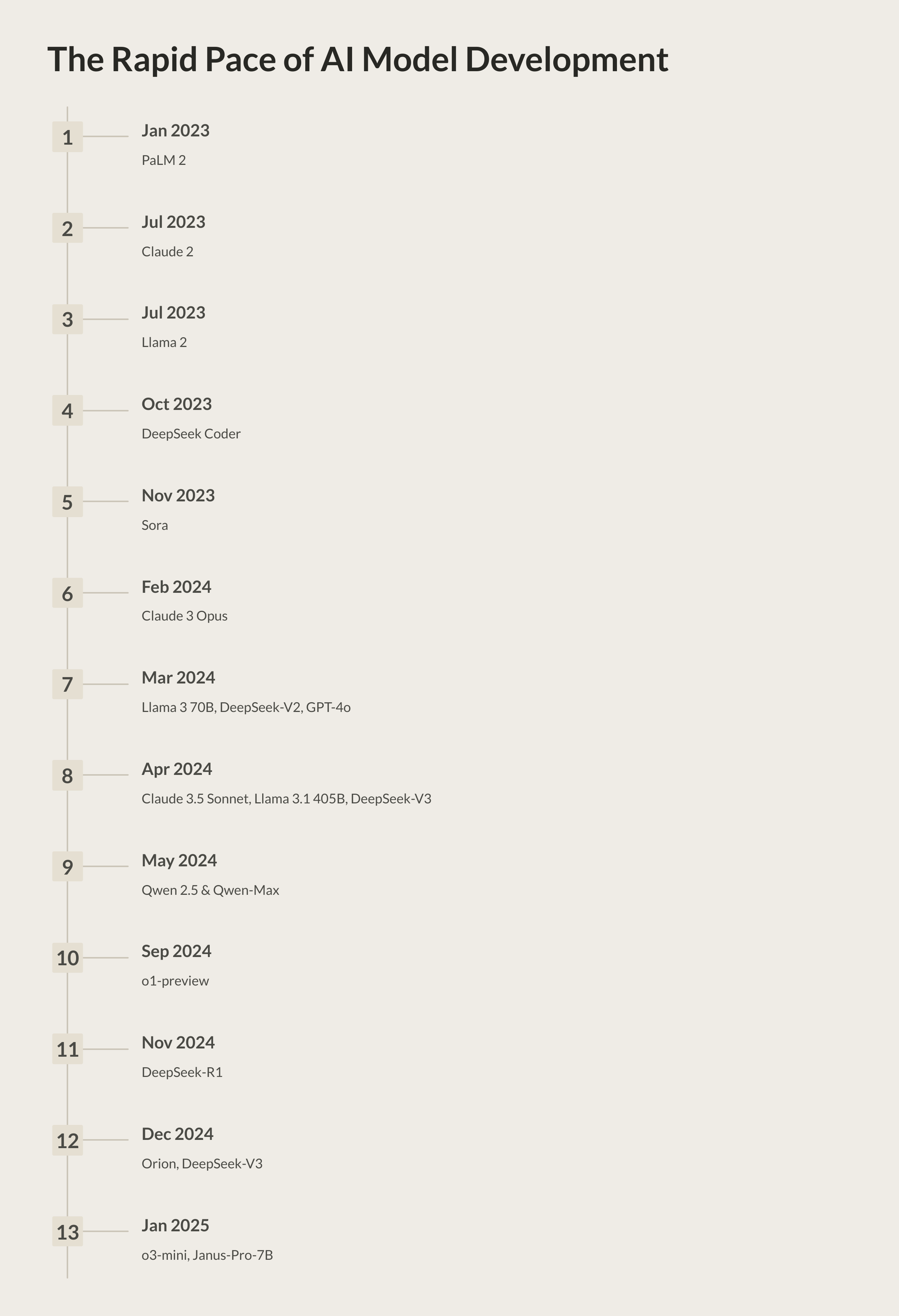
Over the past couple of years, AI startups have gotten used to picking a single foundation model—say GPT4, or a specialized alternative—and then contorting their application and guardrails around it. This was fine when new models arrived once a year; you could thoroughly fine-tune or customize each time. But now, with cutting-edge releases dropping every few months (and model performance often leapfrogging prior state-of-the-art), that one-model approach has become a liability.
Model Timeline Acceleration
Closed-source leaps: Larger, well-funded entities keep rolling out proprietary models with impressive capabilities.
Open-source momentum: Meanwhile, the open-source community produces more models, some surprisingly close in performance to commercial ones—especially at specific tasks.
The gap shifts almost monthly, making it hard to bet everything on one system. If your application is tightly coupled to a single model, you end up re-engineering your entire product whenever a new contender emerges. That’s a recipe for near-constant disruption and wasted development cycles.

Pick Your Side—Wrapper or Model Provider
To paraphrase Bill Gurley, technology markets often favor either those who own the transformative tech or those who aggregate it best. If you’re an old-school model-training shop, you once asked customers for proprietary data in exchange for specialized AI solutions (like Datarobot). But today, you’re going head-to-head against foundation models trained on nearly the entire internet. They enjoy scale advantages—both in pre-training and in the sheer resources behind them as well as test time compute.
On the other hand, if you build on the application layer—aggregating, orchestrating, or “wrapping” multiple models—your advantage is flexibility. You can slot in the newest or most cost-effective model as soon as it becomes viable. But being in the middle can be tough: you risk repeated context switching and re-tuning if you aren’t designing your system from the outset to be model-agnostic.
Practical Implications
Model-Agnostic Infrastructure: We’ve reached a point where it’s dangerous to rely on too many idiosyncrasies of any single model. Instead, design an agent that can route tasks to the best model for each job—or at least let your users choose, as the coffee shop conversation illustrated.
Cost vs. Performance: If a new open-source model can match 80% of the performance of a top-tier commercial offering at half the cost, that might revolutionize the unit economics of your startup. Don’t overfit your entire pipeline to a single model you can’t swap out.
Guardrails at a Higher Level: Don’t bake your application logic so deeply into one model’s architecture that you can’t pivot. Instead, handle domain-specific guardrails and user flows above the model layer. This also creates a more transparent, modular design that fosters user trust.
Continuous Evaluation: The days of annual revalidations are gone. You’ll need a robust, automated system to continuously test new releases and measure them against your core metrics. That’s the only way to keep up with the breakneck tempo of new model launches.
Final Thoughts
All of this points to a broader theme underscored by Ben Thompson’s aggregation theory and the swift shifts we see in AI markets: the value is consolidating at two ends—those who command the greatest scale in training (the model providers) and those who are best at orchestrating these models for specific verticals or user scenarios (the wrappers). The companies that remain stuck in the middle, or married to a single approach, risk being overshadowed the moment a new model with better performance or economics comes along.
For AI entrepreneurs, there is a clear choice: either build the next foundation model (a daunting, massively capital-intensive task) or become the best aggregator—one that always picks the right model at the right time for the right user need. It’s reminiscent of the “aha moment” we saw with DeepSeek-R1-Zero. Don’t waste time crafting overly specialized “hand-coded solutions.” The real challenge is building frameworks flexible enough to leverage that emergent, unstoppable wave of scale.
As Dario Amodei notes in his reflections on DeepSeek, the questions around how these models were trained—or whether you can replicate them with a $6 million budget—are fascinating but secondary to the practical realities for most builders. The train of progress is moving fast. Your job is to pick a side.